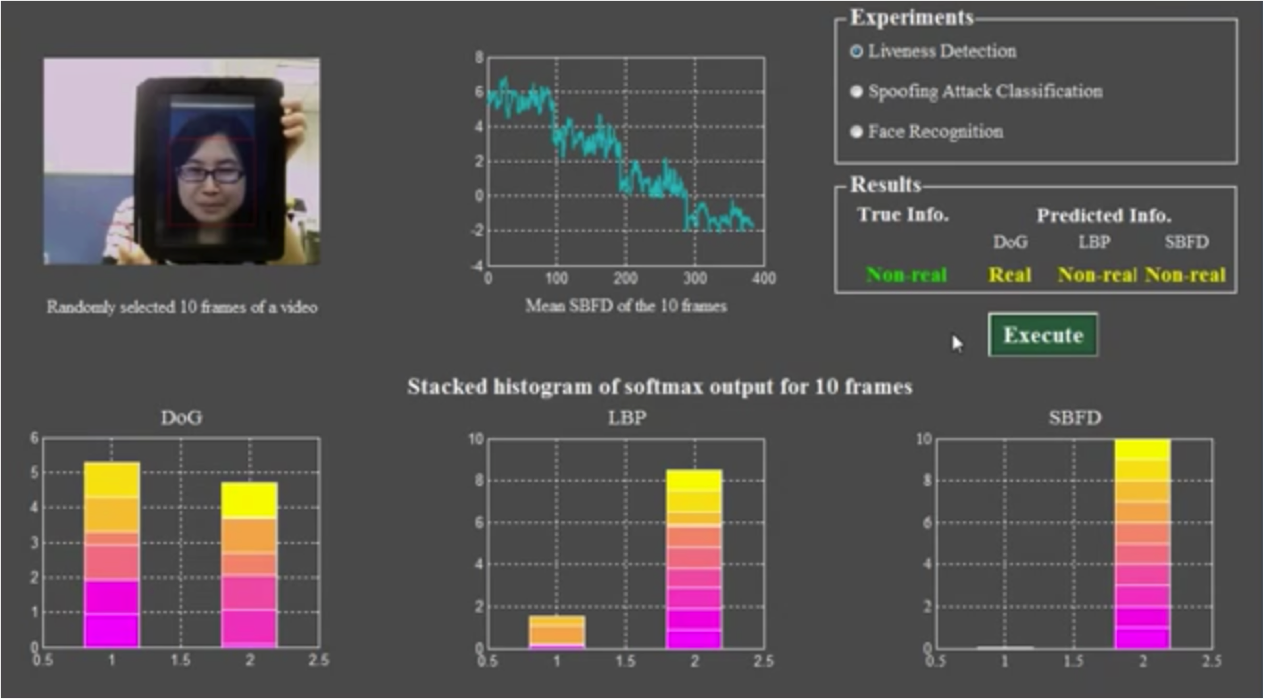
Face recognition is a widely used biometric technology due to its convenience but it is vulnerable to spoofing attacks made by non-real faces such as a photograph or video of valid user. Anti-spoof problem must be well resolved before widely applying face recognition in our daily life. In which, face liveness detection is a core technology to make sure that the input face is a live person. However, this is still very challenging using conventional liveness detection approaches of texture analysis and motion detection. The aim of this paper is to propose a feature descriptor and an efficient framework which can be used to effectively deal with face liveness detection problem. In this framework, new feature descriptors are defined using a multiscale directional transform (shearlet transform). Then, stacked autoencoders and softmax classifier are concatenated to detect face liveness. We evaluated this approach using CASIA Face Anti-Spoofing Database and Replay-Attack database. The experimental results show that our approach performs better than state-of-the-art techniques following the provided evaluation protocols of these databases, and is possible to significantly enhance the security of face recognition biometric system. In addition, experimental results also demonstrate that this framework can be easily extended to classify different spoofing attacks.
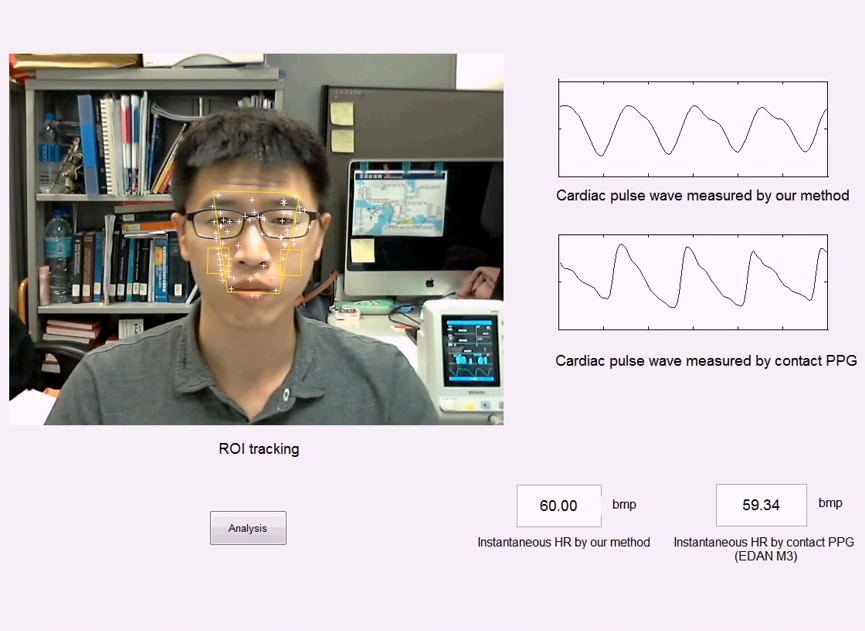
Remote Photoplethysmography (rPPG) can achieve contactless monitoring of human vital signs. However, the robustness to a subject's motion is a challenging problem for rPPG, especially in facial video-based rPPG. Based on the optical properties of human skin, we build an optical rPPG signal model in which the origins of the rPPG signal and motion artifacts can be clearly described. The region of interest (ROI) of the skin is regarded as a Lambertian radiator. By considering a digital color camera as a simple spectrometer, we propose an adaptive color difference operation between the green and red channels to reduce motion artifacts. Based on the spectral characteristics of PPG signals, we propose an adaptive bandpass filter to remove residual motion artifacts of rPPG. We also combine ROI selection on the subject's cheeks with speeded-up robust features points tracking to improve the rPPG signal quality.
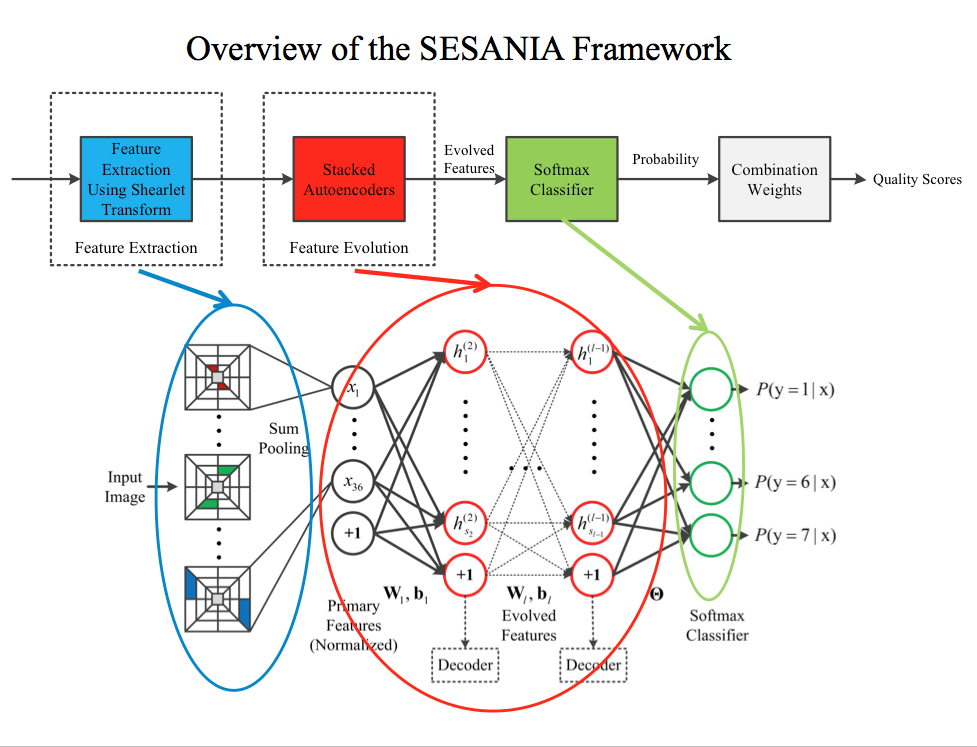
In this work we propose an efficient general-purpose no-reference (NR) video quality assessment (VQA) framework which is based on 3D shearlet transform and Convolutional Neural Network (CNN). Taking video blocks as input, simple and efficient primary spatiotemporal features are extracted by 3D shearlet transform, which are capable of capturing the Natural Scene Statistics (NSS) properties. Then, CNN and logistic regression are concatenated to exaggerate the discriminative parts of the primary features and predict a perceptual quality score. The resulting algorithm, which we name SACONVA (SheArlet and COnvolutional neural network based No-reference Video quality Assessment), is tested on well-known VQA databases of LIVE, IVPL and CSIQ. The testing results have demonstrated SACONVA performs well in predicting video quality and is competitive with current state-of-the-art full-reference VQA methods and general-purpose NR-VQA algorithms. Besides, SACONVA is extended to classify different video distortion types in these three databases and achieves excellent classification accuracy.
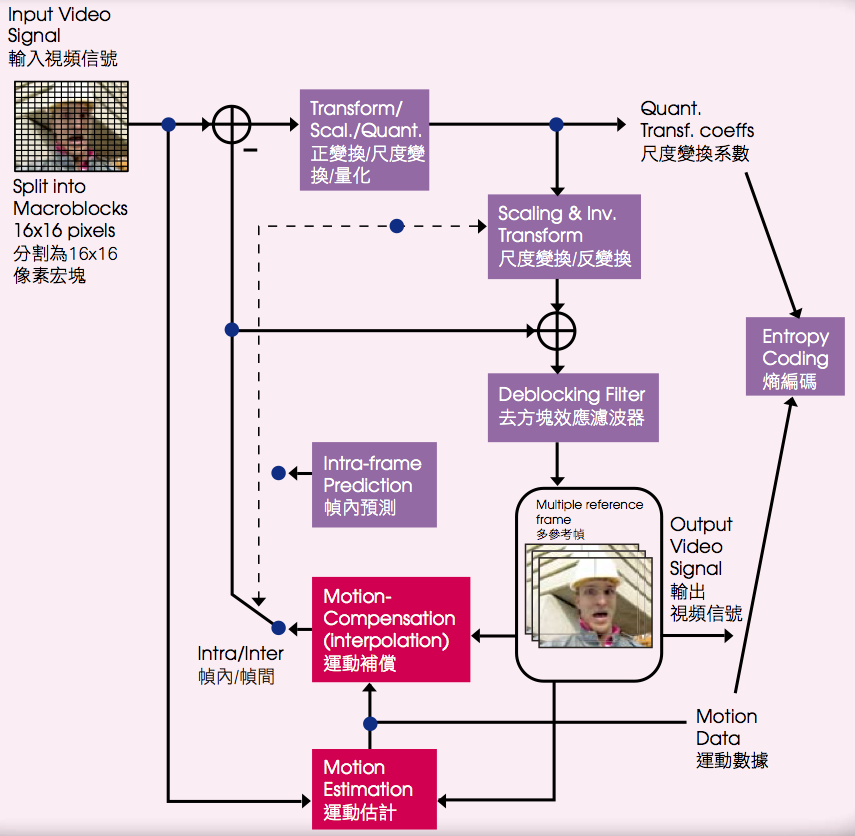
In multiview video coding (MVC), disparity-compensated prediction (DCP) exploits the correlation among dif- ferent views. A common approach is to use block-based motion- compensated prediction (MCP) tools to predict the disparity effect among different views. However, some regions in different views may have various deformations due to nonconstant depth. Thus, performance of DCP is not satisfactory with the simple translational model assumed in conventional block-based MCP tools. Previous attempts to achieve better disparity prediction were usually too complex for practical use. In this project, horizontal scaling and shearing (HSS) effects are investigated to increase interview prediction accuracy for stereo video. HSS deformations are common among images of horizontally aligned views, due to horizontal and vertical flat surfaces that are not parallel with projection image planes. To achieve HSS-based DCP with minimal complexity, an efficient subsampled block-matching technique is adopted and integrated into MVC extension of H.264/AVC in stereo profile. Affine parameters estimation and additional frame buffers are not required and the overall increase of computational complexity and memory requirements are moderate. Experimental results show that the new technique can achieve up to 5.25% bitrate reduction in i nterview prediction using JM17.0 reference software implementation.
PhD positions are available for self-motivated applicants at all levels with strong interest in conducting original research. Prior experiences in signal processing or image/video processing would be preferred. Applications are considered throughout the year until vacancies are filled. Applicants are encouraged to send a full CV through email to eelmpo@cityu.edu.hk